Andy Marek, Making of
Zu seinem 45., 50. und 55. Geburtstag schenkte ich Andy Marek Collagen und zu seinem 60. Geburtstag war ein Fotobuch mit allen je hergestellten Fotos geplant. Leider verließ aber Andy Rapid schon mit 57 wegen einer schwerwiegenden Erkrankung. Daher musste dieses Fotobuch früher hergestellt werden und ich habe es ihm an seinem Abschiedsabend am 15. Februar übergeben.
Nun, ein Fotobuch zu erstellen, ist heutzutage eine relativ einfache Übung, gibt es doch bei jedem Fotogeschäft Programme, mit denen man solche Bücher interaktiv herstellen kann.
Das hier beschriebene Fotobuch ist aber etwas anders, einmal, weil es sehr viele Bilder umfasst (ca. 4000) und die Bilder chronologisch geordnet und auch beschriftet sein sollen, also mit Datum und Anlass. Wegen großen Zahl der Bilder ist Handarbeit keine gute Idee, ein Programm soll das erledigen. Es sind mindestens 2.500, wahrscheinlich aber noch viel mehr. Von wo ich die Anzahl der Bilder weiß? Nun, ich verwende immer noch das eigentlich nicht mehr weiter in Entwicklung befindliche Programm Picasa von Google. Picasa hat eine hervorragende Gesichtserkennung eingebaut. (Ich habe die Gesichtserkennungen von Adobe Lightroom und auch eines anderen Programms versuchsweise in Betrieb genommen, doch ich war von deren mangelhaften Qualität und Geschwindigkeit ziemlich enttäuscht.)
Die Gesichtserkennung funktioniert bei Picasa vollautomatisch. Vom Programm automatisch erkannte Gesichter werden in einem Katalog angelegt. Anfangs sind die Gesichter natürlich nicht benannt aber bereits nach Personen geordnet. Wenn man nun einem von Picasa gefundenen Gesicht einen Namen zuordnet, findet Picasa im Laufe der Zeit ohne einen bemerkbaren Leistungsabfall alle Vorkommen dieses Gesichts in der Fotosammlung. Wenn ein Bild übersehen wurde, kann man es händisch ergänzen. Wenn Picasa unsicher ist, kann man ein fragliches Gesicht bestätigen oder ablehnen.
Alle benannten Gesichter werden automatisch in einem Album zusammengefasst, und dieses Album kann man auf zwei Arten betrachten:
- in der Porträtansicht und
- in der Originalbildansicht
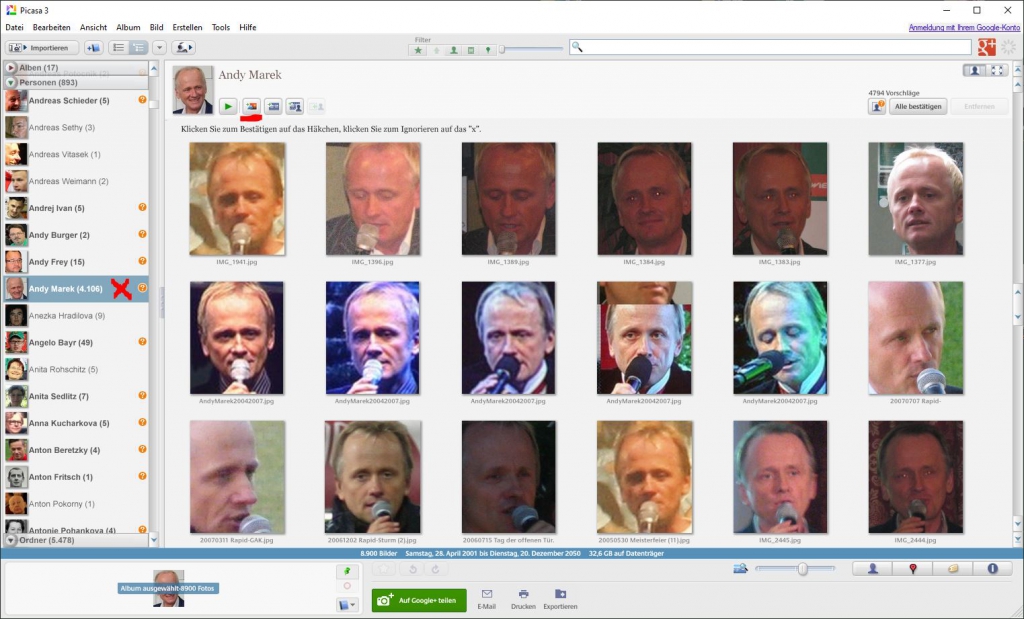
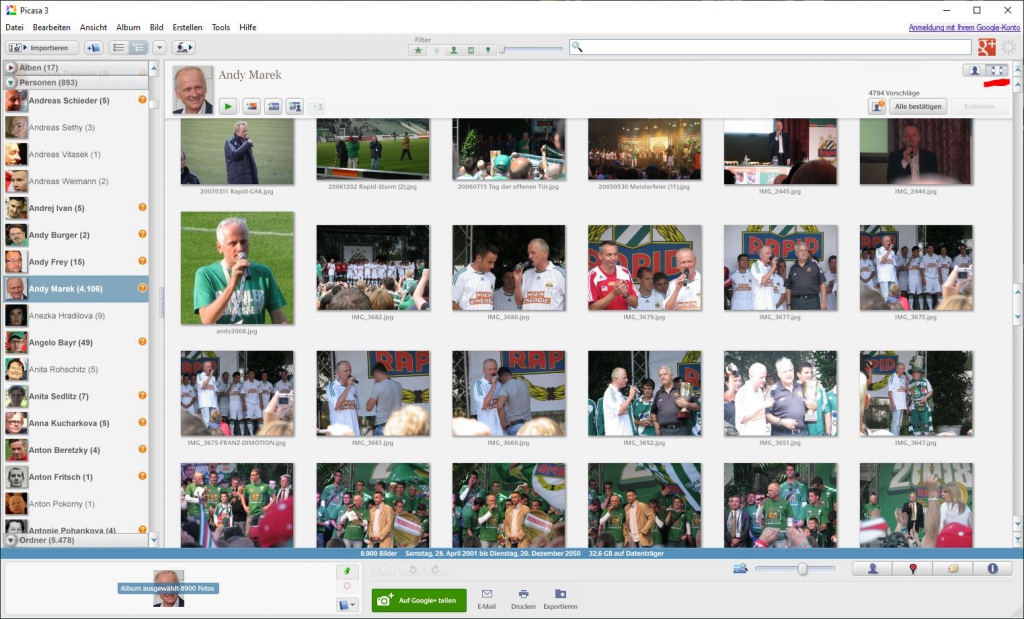
Der Plan war, jeweils ein Porträt und das zugehörige Originalbild chronologisch in einem Bilderbuch zusammenzufassen.
Dieses Album mit allen Porträts einer bestimmen Person kann man als Webseite exportieren (Album -> Als Webseite exportieren). Das folgende Bild zeigt dieses von Picasa automatisch hergestellte Album:
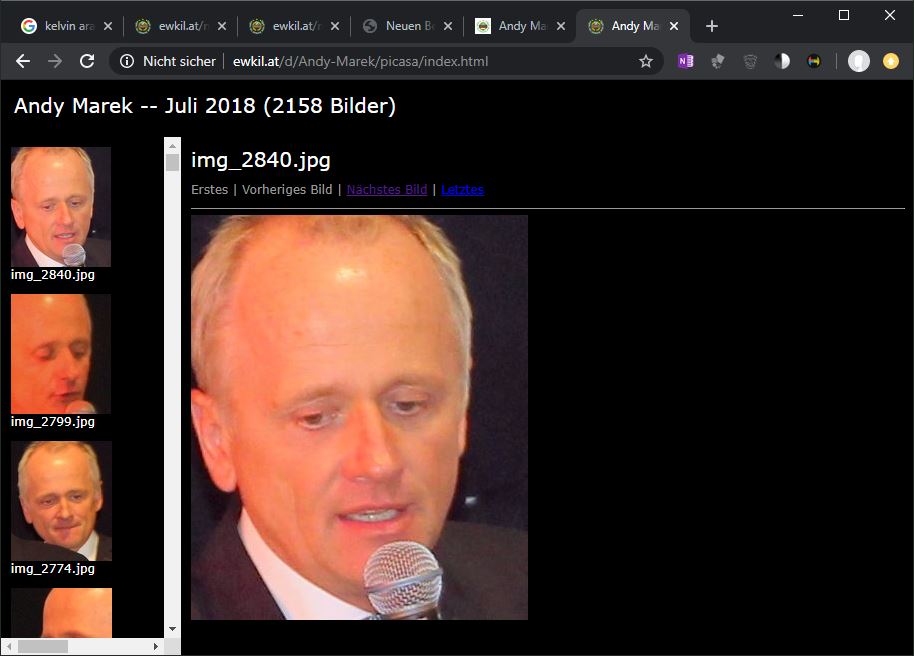
http://ewkil.at/d/Andy-Marek/picasa/index.html
Das ist schon sehr schön, aber es ist eine ungeordnete Anordnung von Porträts ohne Datum und ohne einen Titel, der den Anlass nennt, an dem das Foto entstanden ist.
Bilderordnung
Meine Bildersammlung ist so aufgebaut, dass jeder Ordner, in dem sich Bilder befinden, Datum und Anlass enthält, also zum Beispiel bei Familienfotos 2019-11-20 Wiener Hütte und bei Rapid-Veranstaltungen ebenso 2019-12-08 Rapid-Austria.
Darüber hinaus gibt es eine strukturelle Ordnung und in sehr großen Verzeichnissen wird eine dekadische und jährliche Struktur eingefügt:
s:\onedrive\
Familie
...
Großelterngeneration
...
Elterngeneration
...
Wir
2010=2019
2019
...
2019-11-20 Wiener Hütte
...
Fußball
Nationalmannschaft
...
Groundhopping
...
Rapid
Rapid (Verein)
...
Rapid I
...
2010=2019
2019
...
2019-12-08 Rapid-Austria
...
Rapid II
...
Ein bestimmtes Bild hat also folgenden Pfad:
s:\onedrive\fußball\rapid\rapid i\2010=2019\2019\2019-12-08 Rapid-Austria\IMG4711.jpg
Man sieht, dass alle Bilder am Onedrive gespeichert werden, sodass man auf allen Endgeräten darauf zugreifen kann.
Aus diesen etwa 200.000 Bildern über Fußball, die sich im Laufe der Jahre angesammelt haben, hat Picasa vollautomatisch die Gesichter aller Rapid-Spieler und -Funktionäre herausgesucht und für „Andy Marek“ etwa 2.500 Porträts gefunden und in einem Album „Andy Marek“ zusammengefasst.
Es gibt also zwei Bilder:
– das Originalbild, die Szene in der „Andy Marek“ gefunden wurde und
– das Portrait, ein Bildausschnitt, das nur das Gesicht enthält.
Speichert man nun das Album mit allen Bildern einer Person, besteht dieses Album nicht aus den Originalbildern, sondern aus den Porträts, die aus dem ursprünglichen Bild herausgeschnitten worden sind. Das Bild selbst wird nicht gespeichert. Man weiß also bei den Portraits nicht, aus welchem Originalbild sie stammen. Glücklicherweise verfügt aber dieses Programm auch noch über eine unbedeutend scheinende Option, die Bildangaben auch in einer XML-Datei zu speichern und diese XML-Datei (hier nicht abgebildet) enthält neben dem Namen des Porträts auch den Bildpfad zu Originaldatei. Diese XML-Datei enthält pro Bild ca. 80 Zeilen und eine dieser Zeilen enthält den oben gezeigten Pfad.
Zur Bearbeitung der Texte wird Visual Studio Code verwendet.
Gewünscht ist eine Liste dieser Bilderpfade ohne die restlichen 79 Zeilen. In der Datei ist also alles zu löschen, was kein Pfad ist. Die Zeilen sind daran zu erkennen, dass sie mit s:\\onedrive\\fußball\ beginnen, alle anderen Zeilen sind zu löschen. Natürlich nicht händisch, sondern mit einem Löschautomaten mit einem regulären Ausdruck.
Normalerweise sucht man etwas und dann arbeitet man damit weiter. In diesem Fall ist es aber umgekehrt, man sucht alle Zeilen, die den Ausdruck s:\\onedrive\\fußball nicht enthalten und diese Zeilen löscht man dann.
Als Editor wird Visual Studio Code benutzt.
Suchen: ^(?!.*s:\\onedrive\\fußball.*).+$\n
Ersetzen:
Danach besteht das Dokument nur mehr aus Leerzeilen und den gesuchten Zeilen. Die Leerzeilen löscht man durch mehrmaliges Anwenden von
Suchen: \n\n
Ersetzen: \n
Jetzt sortiert man die Bilder alphabetisch und erhält
Der nächste Schritt ist die Herstellung einer Datenbankstruktur. Der Pfad ist eines der Spaltenelemente aber es werden noch die Felder „Jahr“, „Datum“, „Anlass“ und „Bilddatei“ benötigt, und diese Felder muss man aus dem Pfad extrahieren. Die Variablen $1 und $2 sind die Werte der eingeklammerten Abschnitte im regulären Ausdruck, $0 ist der Ausdruck selbst, also der Pfad des Bildes:
Suchen: .+?\\([0-9][0-9][0-9][0-9])\\([0-9][0-9][0-9][0-9]-[0-9][0-9]-[0-9][0-9]) (.+)\\(.+)
Ersetzen: $1\t$2\t$3\t$4\t$0
Man erhält die Felder jahr datum anlass bild pfad
Diese Datenbank im CSV-Format dient als Grundlage für die Herstellung des Fotobuchs. Sie wird als images.csv gespeichert.
Das Fotobuch soll sowohl online als HTML-Datei als auch in ausgedruckter Form als Word- und PDF-Datei hergestellt werden.
Fotobuch
Natürlich könnte man zum Beispiel eine .rtf-Datei erstellen oder mit den Bordmitteln von Word, dem Visual Basic, eine Word-Datei zusammenbasteln. Da aber später auch eine HTML-Datei für die Publikation im Web entstehen soll, wird zuerst eine HTML-Datei für die Publikation im Web erstellt und diese dann in Word importiert. Es ist erstaunlich, wie einfach das geht.
Erstellt wird zuerst eine HTML-Datei ohne weitere Formatierung, die jeweils ein Porträt und das dazugehörige Originalbild enthält. Diese Datei wird danach in Word importiert und die für einen Ausdruck erforderlichen zusätzlichen Formatierungen angebracht.
Damit nun alle Bilder für dieses Fotobuch in einem einzigen Verzeichnis versammelt sind, werden die Originale aus dem Archivverzeichnis auf den Desktop kopiert.
Die im Zuge der Herstellung der xml-Datei durch Picasa hergestellte Struktur ist wie folgt:
Andy Marek - xml images thumbnails index.xml
In images sind alle Porträts in größtmöglicher Auflösung, in thumbnails sind Vorschaubilder davon. Die Originalbilder werden von Picasa nicht gespeichert. Daher wurde der zusätzliche Ordner originals angelegt und durch ein Skript werden die Originalbilder aus dem Archiv geholt und in den Ordner originals kopiert.
#Kopieren aller Original-Bilder aus dem Archiv in ein gemeinsames verzeichnis
Clear-Host
$TAB = [char]9
$images_path = "S:\OneDrive_Franz\OneDrive\Desktop\Andy Marek - xml\"
$images_csv = "images.csv"
$images_path_original = "original\"
$count = 0
$images_path_original = $images_path + $images_path_original
"start copying files from archive to $images_path$images_path_original"
$images_csv = $images_path + $images_csv
foreach($line in Get-Content $images_csv -Encoding UTF8) {
$line_parts = $line.Split($TAB)
$From = $line_parts[4].Replace("\odrive\","\OneDrive_Franz\")
$PathExists = Test-Path $From -PathType Leaf
if (-not $PathExists) {
$From
}
$To = $images_path_original + $line_parts[3]
Copy-Item -Path $From -Destination $To
$count++
if ($count -eq 2500) { break }
}
"$count files copied"
Es gibt jetzt zwei Verzeichnisse mit Bildern:
images: Portraits
originals: Originalbilder aus denen die Portraits ausgeschnitten worden sind
Für eine einheitliche und für das Internet angepasste Größe der Bilder werden alle Bilder im Verzeichnis originals mit IrfanView verkleinert und die Verkleinerung im Verzeichnis originals-small gespeichert.
Jetzt sind zwei Html-Dateien gesucht:
- für den Import in Word
- für die Darstellung im Internet
Man könnte meinen, dass es genügt, eine solche Datei zu generieren, aber leider ist das nicht so, weil die Anforderungen an eine ans Endgerät anpassbare („responsive“) Web-Datei ziemlich groß sind und die damit einher gehenden JavaScript-Codes von Word nicht korrekt verarbeitet werden. Daher benötigt man für den Import in Word eine einfachere, direkt formatierte HTML-Datei und für die Web-Version eine responsive-Version.
Word-Version
Der nächste Schritt ist die Herstellung einer HTML-Datei, die auf alle diese Bilder verlinkt und die Bilder auf eine einheitliche Größe skaliert und die Bilder mit Datum und Titel beschriftet. Aus Vorversuchen hat sich ergeben, dass die HTML-Datei möglichst einfach strukturiert sein muss. Das für den Export verwendete Programm heißt images-word.ps1:
Clear-Host
add-type -AssemblyName System.Drawing
$TAB = [char]9
$CRLF = [char]13 + [char]10
$height = 180
$width_left = 300
$width_right = 400
$images_path = "S:\OneDrive\Projekte\ewkil\data\Andy Marek\"
$images_csv = "images.csv"
$images_out = "images.html"
$images_path_original = "original-small\"
$images_path_portrait = "images\"
$images_path_original = $images_path + $images_path_original
$images_path_portrait = $images_path + $images_path_portrait
$images_path_html = $images_path + $images_out
$images_csv = $images_path + $images_csv
$count = 0
"starting"
$html = "<body>$CRLF<table>$CRLF"
foreach($line in Get-Content $images_csv -Encoding UTF8) {
$line_parts = $line.Split($TAB)
[int]$n = $line_parts[0]
[int]$show = $line_parts[1]
if ($show -eq 0) { continue }
$count++
$Date = $line_parts[3]
$Date = $Date.Substring(6,4)+"-"+$Date.Substring(3,2)+"-"+$Date.Substring(0,2)
$Event = $line_parts[4]
$Name = $line_parts[5]
if ($count -gt 100) {
#break
}
$image_portrait = $images_path_portrait + $Name
$PathExists = Test-Path $image_portrait -PathType Leaf
$ErrorFileName = $false
if (-not $PathExists) {
$image_portrait = $images_path_portrait + $Name.Replace(" ","_")
$PathExists = Test-Path $image_portrait -PathType Leaf
if (-not $PathExists) {
"ERROR PORTRAIT : $Count $Name"
$ErrorFileName = $true
}
}
$image_original = $images_path_original + $Name
$PathExists = Test-Path $image_original -PathType Leaf
if (-not $PathExists) {
$image_portrait = $images_image_original + $Name.Replace(" ","_")
$PathExists = Test-Path $image_original -PathType Leaf
if (-not $PathExists) {
"ERROR ORIGINAL : $Count $Name"
$ErrorFileName = $true
}
}
if ($ErrorFileName) { continue }
$image = New-Object System.Drawing.Bitmap $image_portrait
$imageWidth_portrait = $image.Width
$imageHeight_portrait = $image.Height
$image = New-Object System.Drawing.Bitmap $image_original
$imageWidth_original = $image.Width
$imageHeight_original = $image.Height
#Kontrollausgabe
#"$Year $Date $Scope $Event"
#"$images_portrait$fname$CRLF"
$width_portrait = [math]::Round((1.0*$imageWidth_portrait*$height)/$imageHeight_portrait)
$width_original = [math]::Round((1.0*$imageWidth_original*$height)/$imageHeight_original)
$html +=
"<tr><td>$Date</td>`
<td> </td><td style='background-color:green;'></td><td> </td>`
<td>$Event</td></tr>" + $CRLF
$html += "<tr><td width='$width_left'>`
<img src='$image_portrait' height='$height' width='$width_portrait' /></td>`
<td> </td><td style='background-color:green;'></td><td> </td>`
<td width='$width_right'><img src='$image_original' height='$height' width='$width_original' /></td></tr>" + $CRLF
#$html +=
#"<tr height='6'><td class='sep'></td>`
#<td></td><td style='background-color:green;' class='sep'></td><td class='sep'></td>`
#<td class='sep'></td></tr>" + $CRLF
}
$html += "</table>"
$Count
$html > $images_path_htmlEine der ca. 2000 Tabellenzellen hat folgenden Aufbau:
Jede Zeile enthält vier Tabellenzellen. Die beiden mittleren haben nur die Aufgabe, einen senkrechten Strich als gestalterisches Element einzufügen.
Der Import in Word ist erstaunlich einfach: man ruft diese HTML-Datei im Browser auf, markiert den ganzen Inhalt und kopiert ihn in Word. Abgesehen von der Wartezeit für die 4000 importieren Bilder hat man damit eine perfekte Word-Datei
images.html 1.972 kB
images-word.docx 223.323 kB
Die in der Html-Datei nur verlinkten Bilder werden in Word durch das Importieren eingebettet und dadurch hat die Word-Datei ca. 220 MB und ist dadurch ein bisschen träge in der Verarbeitung.
Kleine kosmetische Operationen müssen noch durchgeführt werden.
Man ordnet dem ganzen Dokument die Formatvorlage Standard zu:
Tabelle markieren -> Formatvorlage Standard wählen
Damit werden alle Tabellenzellen einheitlich formatiert, auch die Bilder. Stellt man daher einen oberen Zeilenrand von 12pt ein, dann haben diesen Rand nicht nur die Textzeilen, sondern auch die Bilder. Das ist unerwünscht. Nun könnte man alle Tabellenzellen, die Bilder enthalten, mit Bildern markieren und mit einem neu erstellten Format „Bild“ versehen. Da es aber 2000 Zeilen gibt, muss man das anders lösen.
Word bietet in der Suchen/Ersetzen-Funktion an, dass man auch nach Grafiken suchen kann. Diese Funktionalität benutzt man in diesem Fall und ersetzt jedes gefundene Bild durch „das gefundene Objekt“ (also das Bild) und vergibt über die Format-Option das soeben erstellte Absatzformat „Bild“. Damit kann man Bilder und Texte unabhängig voneinander formatieren.
Bilder auf einer Seite
Die Bildhöhe wurde mit 180px gewählt. Auf einer A4-Seite ergibt das gerade vier Bildzeilen mit der dazugehörigen Bildüberschrift bestehend aus Datum und Anlass. Der Abstand von jeder Textzeile wird so gewählt, dass die fünfte Tabellenzelle bereits auf die nächste Seite zu liegen kommt.
Abschließend wird die Textausrichtung der linken Tabellenspalte auf rechtsbündig eingestellt. Kopf- und Fußzeile werden eingegeben und das Word-Dokument ist fertig. Ein Titelblatt komplettiert das Projekt.
Beispielseite

Herstellung
Für die Herstellung farbige Dokumente benutze ich die Dienste eines nahe gelegenen Copyshop. Dort wird das Projekt auch gleich mit einer Plastikspirale gebunden: https://www.2print.at/
PDF-Version
http://ewkil.at/d/andy-marek/AM-print.pdf (Achtung: 225 MB)
Das Gesamtprojekt besteht aus einem Deckblatt, einem Statistikteil und aus dem hier beschriebenen Bilderbuch.
Webversion herstellen
Im Grunde gibt es nun schon eine Html-Version, aber leider ist diese Datei für das Web nicht gut geeignet, weil die Ladezeit für 2000 Bilder einfach zu groß ist. Daher wird für das Web die Datei in einzelne Jahre unterteilt, die über ein Menü aufrufbar sind.
Ein weiterer wichtiger Aspekt einer Html-Datei für die Publikation ist ihre Anpassbarkeit an verschieden große Bildschirme („responsiveness“), insbesondere auch an Handys. Wenn man da beginnen würde herumzuprogrammieren, wäre allein das Arbeit für ein ganzes Jahr. Daber benutze ich zur Unterstützung der Endgeräteanpassung das Programmpaket „bootstrap 4.0“. Das Paket sorgt dafür, dass Bilder und Texte sich dem verfügbaren Platz gut anpassen. Dass sich die Bilder in einer starren Tabelle befinden, ist nicht vorteilhaft, wird aber nicht geändert.
Für eine kompakte und übersichtliche Größe wird die Html-Seite durch ein JavaScript-Programm erstellt, damit sind Darstellungsänderungen extrem einfach möglich. Die verwendete Bibliotheken sind bootstrap 4.0 und
jQuery
Programm
<!DOCTYPE html>
<html lang="de" xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>Andy Marek Bildersammlung</title>
<meta name="viewport" content="width=device-width, initial-scale=1, minimum-scale=1.0, maximum-scale=2.0, user-scalable=yes" />
<link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.4.1/css/bootstrap.min.css" integrity="sha384-Vkoo8x4CGsO3+Hhxv8T/Q5PaXtkKtu6ug5TOeNV6gBiFeWPGFN9MuhOf23Q9Ifjh" crossorigin="anonymous">
<link href="https://fonts.googleapis.com/css?family=Fira+Sans:400,300,500&subset=latin" rel="stylesheet" type="text/css" />
<script src="https://code.jquery.com/jquery-3.4.1.slim.min.js" integrity="sha384-J6qa4849blE2+poT4WnyKhv5vZF5SrPo0iEjwBvKU7imGFAV0wwj1yYfoRSJoZ+n" crossorigin="anonymous"></script>
<script src="https://cdn.jsdelivr.net/npm/popper.js@1.16.0/dist/umd/popper.min.js" integrity="sha384-Q6E9RHvbIyZFJoft+2mJbHaEWldlvI9IOYy5n3zV9zzTtmI3UksdQRVvoxMfooAo" crossorigin="anonymous"></script>
<script src="https://stackpath.bootstrapcdn.com/bootstrap/4.4.1/js/bootstrap.min.js" integrity="sha384-wfSDF2E50Y2D1uUdj0O3uMBJnjuUD4Ih7YwaYd1iqfktj0Uod8GCExl3Og8ifwB6" crossorigin="anonymous"></script>
<style>
body {
color:white;
background-image: url("unter5.png");
}
p, td {
font-size: larger;
font-weight: bold;
}
.td_left {
width:300pt;
height:20pt;
text-align:right;
}
.td_right {
width:400pt;
height:20pt;
text-align:left;
}
.td_left_i {
width:300pt;
text-align:right;
}
.td_right_i {
width:400pt;
text-align:left;
}
.imgheight {
height:170pt;
}
.nav {
background-color: white;
}
.imgori {
width:100%
}
.background {
background-color:green;
}
</style>
<script src="images-html.js"></script>
<script>
var getUrlParameter = function getUrlParameter(sParam) {
var sPageURL = window.location.search.substring(1),
sURLVariables = sPageURL.split('&'),
sParameterName,
i;
for (i = 0; i < sURLVariables.length; i++) {
sParameterName = sURLVariables[i].split('=');
if (sParameterName[0] === sParam) {
return sParameterName[1] === undefined ? true : decodeURIComponent(sParameterName[1]);
}
}
};
function GetTable(tr) {
return "<table class='table table-dark'>\r\n" + tr + "</table>\r\n"
}
function GetRow(td1,td2) {
return "<tr>"
+ td1
+ "<td style='width:12pt;'> </td>"
+ "<td style='width:1pt;background-color:white;'> </td>"
+ "<td style='width:12pt;'> </td>"
+ td2
+ "</tr>"
}
function GetData1(d) {
return "<td class='td_left'>" + d + "</td>"
}
function GetData2(d) {
return "<td class='td_right'>" + d + "</td>"
}
function GetImg1(img) {
return "<td class='td_left_i img-thumbnail bg-transparent'>"
+ "<img src='images/" + img + "'' class='imgheight' />"
+ "</td>"
}
function GetImg2(img,n) {
return "<td class='td_right_i imgheight img-thumbnail bg-transparent'>"
+ "<img class='imgheight lightbox' id='id" + n + "' src='original-small/" + img + "' />"
+ "<div id='m" + n + "' class='modal fade bd-example-modal-xl' tabindex='-1' role='dialog' aria-labelledby='myExtraLargeModalLabel' aria-hidden='true'>"
+ "<div class='modal-dialog modal-xl' role='document'>"
+ "<div class='modal-content'>"
+ "<img id='id" + n + "' class='imgori img-fluid rounded' src='original-small/" + img + "' />"
+ "</div></div></div>"
+ "</td>"
}
function GetDate(d) {
return d.substring(6)+"-"+d.substring(3,5)+"-"+d.substring(0,2)
}
$(function() {
var f = getUrlParameter('f');
var t = getUrlParameter('t');
var all = getUrlParameter('all');
if (all==1) {
f=2001
t=2020
}
if (f == undefined) {
f=2020
t=2020
}
$("#y"+(all==1?"all":f)).addClass("active")
var count = 0
var countall = 0
var s = ""
for (i in img.dat) {
countall++
if ((img.dat[i].y>=f) && (img.dat[i].y<=t)) {
count++
s += GetRow(GetData1(GetDate(img.dat[i].d)), GetData2(img.dat[i].t))
s += GetRow(GetImg1(img.dat[i].f), GetImg2(img.dat[i].f,img.dat[i].n))
s += GetRow(GetData1("", ""))
}
}
$("#images").html(s)
if (all==1) {
$("#title").html("2001-2020")
$("#count").html(count)
$("#countall0").addClass("d-none")
} else {
$("#title").html(f)
$("#count").html(count)
$("#countall").html(countall)
}
$("#navigation").removeClass("d-none")
$( ".lightbox" ).click(function() {
var id = $(this).attr("id")
id = id.replace("id","m")
$("#"+id).modal({
keyboard: true,
backdrop: true
})
});
$('.list-group-item').on('click', function() {
$("#title").html($(this).html())
})
});
</script>
</head>
<body class="background">
<div class="container-sm">
<div class="row">
<div id="navigation" class="sticky-top background d-none">
<ul class="nav nav-pills">
<li class="nav-item"><a href="images-html.htm?f=2020&t=2020" class="nav-link" id="y2020">2020</a></li>
<li class="nav-item"><a href="images-html.htm?f=2019&t=2019" class="nav-link" id="y2019">2019</a></li>
<li class="nav-item"><a href="images-html.htm?f=2018&t=2018" class="nav-link" id="y2018">2018</a></li>
<li class="nav-item"><a href="images-html.htm?f=2017&t=2017" class="nav-link" id="y2017">2017</a></li>
<li class="nav-item"><a href="images-html.htm?f=2016&t=2016" class="nav-link" id="y2016">2016</a></li>
<li class="nav-item"><a href="images-html.htm?f=2015&t=2015" class="nav-link" id="y2015">2015</a></li>
<li class="nav-item"><a href="images-html.htm?f=2014&t=2014" class="nav-link" id="y2014">2014</a></li>
<li class="nav-item"><a href="images-html.htm?f=2013&t=2013" class="nav-link" id="y2013">2013</a></li>
<li class="nav-item"><a href="images-html.htm?f=2012&t=2012" class="nav-link" id="y2012">2012</a></li>
<li class="nav-item"><a href="images-html.htm?f=2011&t=2011" class="nav-link" id="y2011">2011</a></li>
<li class="nav-item"><a href="images-html.htm?f=2010&t=2010" class="nav-link" id="y2010">2010</a></li>
<li class="nav-item"><a href="images-html.htm?f=2009&t=2009" class="nav-link" id="y2009">2009</a></li>
<li class="nav-item"><a href="images-html.htm?f=2008&t=2008" class="nav-link" id="y2008">2008</a></li>
<li class="nav-item"><a href="images-html.htm?f=2007&t=2007" class="nav-link" id="y2007">2007</a></li>
<li class="nav-item"><a href="images-html.htm?f=2006&t=2006" class="nav-link" id="y2006">2006</a></li>
<li class="nav-item"><a href="images-html.htm?f=2005&t=2005" class="nav-link" id="y2005">2005</a></li>
<li class="nav-item"><a href="images-html.htm?f=2004&t=2004" class="nav-link" id="y2004">2004</a></li>
<li class="nav-item"><a href="images-html.htm?f=2001&t=2001" class="nav-link" id="y2001">2001</a></li>
<li class="nav-item"><a href="images-html.htm?all=1" class="nav-link" id="yall">alle</a></li>
</ul>
</div>
<div class="col">
<h1>Andy Marek <span id="title"></span></h1>
<p><span id="count"></span> Bilder <span id="countall0">von <span id="countall"></span> Bildern</span></p>
<hr class="background" />
<div id="images"></div>
</div>
</div>
</div>
</body>
</html>Programm wurde mit validator.w3c.com geprüft.
Aussehen
Link (selbständige Webseite)
Link (eingebettet in Rapid-Webseite)
http://klubderfreunde.at/rapid/bildprojekte/andy-marek/andy-marek-abschied/
Fehler
Der Zeitdruck für die Herstellung des Bilderbuchs war ziemlich groß und nach fertiggestelltem Word-Dokument wurde ein gravierender Fehler festgestellt. Das Zusammenkopieren aller Original-Dateien in einem Ordner war keine gute Idee. Beim einem Test mit wenigen Bildern war das Problem nicht zu sehen. Aber nachdem alles fertig war, stellte sich heraus, dass immer wieder Porträts nicht zu den jeweiligen Originalen passten. Der Grund waren sich wiederholende Bildnummern, die zu einem Überschreiben bereits kopierter, gleichnamiger Bilder geführt haben. Es gab mehrere Gründe für die Mehrfachnamen:
- Bilder einer Kamera werden fortlaufend nummeriert, daher wiederholen sie sich nicht, könnte man meinen. Aber das trifft nur zu, wenn um wenige Bilder geht. Bei sehr vielen Bildern kommt es zu einem Nummern-Überlauf und daher zu einer Bildwiederholung.
- Über so langen Zeiträumen werden mehrere Kameras und oft auch zwei verschiedene Kameras verwendet, auch dabei kann es zu Überschneidungen der Bildnamen kommen.
- Schließlich werden oft Bildkompositionen hergestellt und diese werden dann mit den phantasielosen Namen bild1.jpg, bild2.jpg versehen. Manch man das in den vielen Jahren mehrfach, kann es auch dadurch zu Überschneidungen bei den Bildnamen kommen.
Für dieses Problem doppelter Bildnamen gibt es ein einfaches Gegenmittel: man muss nur den Bildnamen den jeweiligen Ordnernamen (oder Pfadnamen) voranstellen und damit hat man eindeutige Bildnamen eingestellt. Leider war es für eine Korrektur zu spät, und die fertiggestellten Bilderbücher enthalten immer wieder fehlerhafte Zuordnungen, die durch die doppelten Bildnamen entstanden sind.